| author: | Tom Veldman |
| title: | Learn the deviations: functionality-loss detection in real data |
| company: | NS |
| keywords: | Data mining, Machine Learning, anomaly detection, indsutrial case study, Big Data, algorithmics, Python. |
| topics: | Algorithms and Data Structures , Case studies and Applications , Dependability, security and performance , Other |
| committee: |
Mariëlle Stoelinga
, Inka Locht , Duncan J. Jansen |
| started: | March 2021 |
| end: | June 2021 |
Description
Learn the deviations: functionality-loss detection in real data
Motivation
Real-world data is a real mess. How come tested-and-established theories never fit our observations? How can you predict when all you see is noise? And yet, it is done; but how?
A great deal of human ingenuity is devoted to develop and fit models, that can explain the real world in simpler and elegant ways. Beyond the challenge and intellectual insights, this enables us to predict and control the capabilities of the system. You wouldn't (or shouldn't) drive on a bridge whose resistance wasn’t calculated by engineers; you wouldn't (or shouldn't) step into an elevator that is beyond max carrying capacity.
Physical models come from physical measurements, but then how does one build a model out of messy data? Can you even? Turns out that yes, you can, providing that normal behaviour can be set apart from noise. But what if we’re after abnormal behaviour, and this looks like noise? Can you still come up with a useful model? Let’s find out in a real-world case study, shall we?
Description
|
The general goal of this project is to detect malfunctions |
Our input data comes from sensors and machines that are operating now in the trains that we take to commute: this is as real as it gets. More specifically, you will be trying to predict malfunctions of the Heating, Ventilation, and Air-Conditioning units (aka HVACs) of the VIRM trains operated by NS. So if you do this right, you will enjoy full airco power next summer.

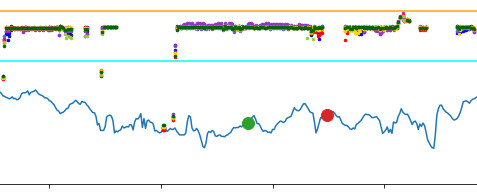
Technically, NS records and stores data of temperature readings from sensors that are next to the ventilation outlets (see Figure 1). These sensors give continuous readings of temperature fluctuations inside and outside the coaches of a train. During hot days, healthy HVACs can keep the temperature inside of the coach at reasonably low values. If the temperature raises too much, it could be an indication of a malfunction of the HVAC (exactly what we want to spot!). Or perhaps it could be that too many people entered the train; or perhaps the clouds moved away and the sunlight heated the train more than it did before... do you see the challenge?
From a scientific perspective, we are talking of time-series data with random noise, which moreover has gaps in certain time frames, plus occasional general spurious behaviour. All of this must not be confused with the temperature deviations caused by malfunctions, that are really indicating an HVAC with functional loss, i.e. with reduced or broken cooling capacity. It is precisely this random noise affecting the temperaturedata, together with suboptimal data quality, that have rendered useless every naïve attempt to classify the informative temperature deviations.
From such input, the mission is to spot periods of time where some of these data points fall clearly outside the normally expected behaviour. These "unhealthy periods" must be chosen so that they indicate an HVAC malfunction, allowing NS to early detect and repair broken HVACs.
Detecting such abnormal behaviour can be done with a data classifier: a machine learning model that is trained to learn which behaviour is normal, and which isn't. A standard approach, some would say, but recall that all our standard approaches have failed so far. The challenge is real! So real in fact, that any data-driven approach that is capable of detecting malfunctions will be accepted by NS. Machine learning is just a promising option.

Assignment
Design, implement, and apply, a program to detect malfunctionsof HVACs in NS, from time-series data on temperature readings.
Details and tasks:
- the input is a set of time-series that describes readings from temperature sensors (see Figure 2), which are locatednext to HVAC units in VIRM trains of NS;
- within a train, these HVACs operate in parallel in similar environmental conditions, so their behaviour (and thus the temperature readings) should be roughly the same;
- your program must be able to detect, from this set of parallel time series, deviated data points that can be justifiably categorised as HVAC malfunctions;
- we only care for too-high temperatures, indicative of cooling malfunctions of the HVACs;
- the proposed approach is to train an ML classifier (you could also try to justify a better alternative), that can operate directly on the real data of NS;
- NS will provide the data to work with, and we will provide essential routines for data extraction and cleaning, to make life easy for you and let you focus in the core task;
- you will work with the Python Pandas library for big data handling, and the Python scikit-learn library for ML applications (this is actually a good thing, trust us);
- your program must minimise false positives (mispredictions) and maximise true positives, because we don't want to send to maintenance a train that is working correctly, right?
- true/false negatives are also to be considered, but they are less important than positives.
The resulting program should detect time-ranges where the temperature readings in a coachare too high, and can be safely classified as an HVAC malfunction.
Key challenges and questions
- Which data classifier fits this data the best?
- How can you handle missing or corrupted data values?
- How can you handle bogus behaviour shown by all data simultaneously?
- How to quantify the quality of the data prediction? (how sure is your classifier)
- How can you make your program understandable? That is, how can you explain the decisions that your program makes?
This has to be used by NS engineers, don't forget. - How can you make this program easy to generalise to other trains and systems?
(a clue for this last one: the less data and your program needs, the more general it is)
References
- A Survey of Outlier Detection Methodologies. (Digital version available here)
- MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks (Digital version available here)
{kind=link}
{kind=link}
{kind=link}